
Yesterday Hortonworks announced Hortonworks 3.0, a big step forward for making Hadoop a more viable option for analytical workloads.
At a high level, Hadoop has historically struggled to perform when SQL-on-Hadoop was used (think IBM Big SQL and Hive), especially compared to the performance of OLAP (cubes or MOLAP) and even star schemas (data warehouses/marts). This meant traditional BI and data biz tools could work on Hadoop but did not perform up to standard. Remember Hadoop is intended to do very big workloads, like aggregation/summation of massive data sets – not joins and filters as BI requires. In Hortonworks 3.0, this has been addressed by supercharging Hive with Apache Druid as a columnar data store, and the details are in the press release I included below.
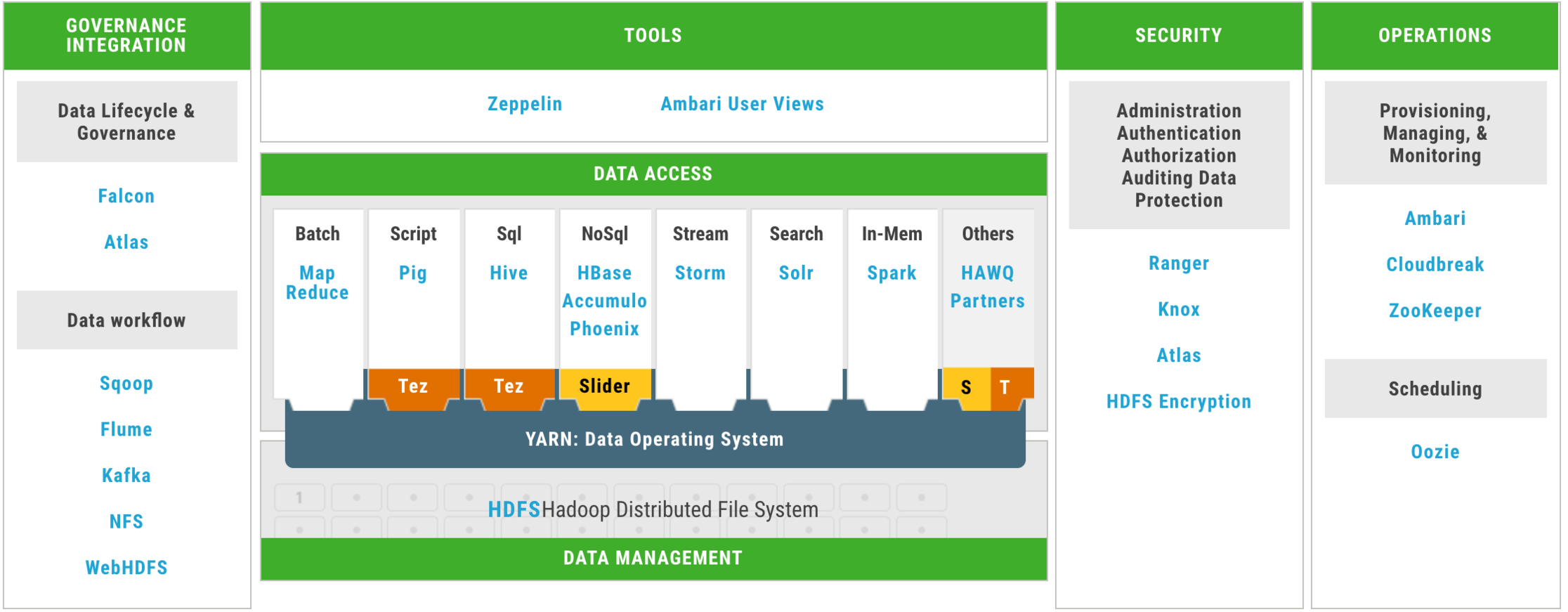
Hortonworks continues to strengthen its partnerships as well, and from IBM there is a brand new service, called IBM Hosted Analytics with Hortonworks (IHAH). This service combines Hortonworks Data Platform, IBM’s Big SQL and the IBM Data Science Experience (Watson Studio).
Details can be found here.
Written by: Chris Foster, Practice Lead, Newcomp Analytics.


